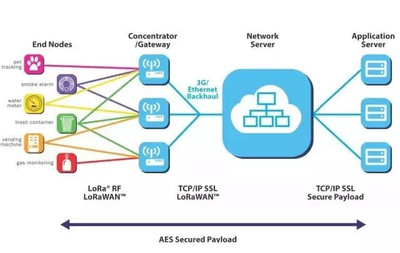
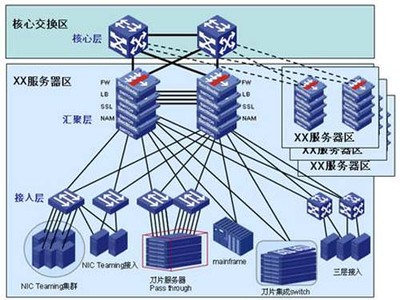
在當今這個數據驅動的時代,大數據技術如同一股洪流,深刻地改變著我們的工作與生活。而要理解大數據的宏偉架構,我們必須從其最基礎、最核心的物理承載者——服務器開始。服務器不僅是存儲與處理海量數據的“心臟”,更是整個大數據生態系統的“地基”。
一、 什么是服務器?
簡單來說,服務器是一臺為網絡中其他計算機或設備(稱為“客戶端”)提供特定服務的高性能計算機。它并非一個神秘的黑盒子,其本質與我們所使用的個人電腦(PC)相似,同樣由中央處理器(CPU)、內存(RAM)、硬盤(存儲)、主板等硬件構成。服務器與PC的關鍵區別在于其設計目標與特性:
- 高穩定性與可靠性:服務器通常需要7x24小時不間斷運行,因此采用更耐用的硬件、冗余設計(如雙電源、RAID磁盤陣列)和更強的散熱系統,以保障服務的持續可用。
- 強大的處理能力與擴展性:為應對成百上千甚至更多的客戶端并發請求,服務器通常配備多核、多路的高性能CPU,大容量內存,并支持通過增加硬件(如更多的CPU、內存條、硬盤)來靈活擴展性能。
- 網絡中心性:服務器生來就是為了聯網和提供服務,其網絡接口的性能和可靠性至關重要。
從形態上,服務器主要分為塔式服務器、機架式服務器和刀片式服務器,后兩者因其高密度、易于集中管理的特性,成為大型數據中心(大數據環境的物理家園)的主流選擇。
二、 服務器在大數據體系中的核心角色
在大數據的語境下,服務器的角色從提供單一服務(如網頁服務)演變為構成龐大計算與存儲集群的節點。大數據處理的核心思想是“分而治之”,即將海量的數據和復雜的計算任務分解,分布到成百上千臺服務器上去并行處理。在這里,服務器扮演著三種關鍵角色:
- 數據存儲的基石:大數據首先意味著“大存儲”。服務器集群構成了分布式文件系統(如Hadoop HDFS)或分布式數據庫的物理基礎。數據被分割成塊,并以多副本的形式存儲在不同服務器的硬盤上,既實現了超大規模存儲,又通過冗余保障了數據安全。
- 計算能力的引擎:大數據的價值通過計算來挖掘。基于MapReduce、Spark等計算框架,計算任務被分發到集群中各臺服務器上,每臺服務器對其本地存儲的數據分片進行計算(“移動計算而非數據”),最后匯果。龐大的服務器集群提供了近乎無限的并行計算能力。
- 服務與協調的中樞:集群中還需要特定的服務器扮演管理協調者的角色,例如Hadoop中的NameNode,或YARN中的ResourceManager。這些“主節點”服務器負責調度任務、監控集群健康、管理元數據等,確保整個大數據系統有序、高效地運轉。
三、 大數據對服務器技術提出的新要求
大數據應用的特有負載,也推動著服務器技術向特定方向演進:
- 橫向擴展(Scale-out)優先:相較于不斷提升單臺服務器的性能(縱向擴展),大數據更傾向于通過增加更多標準化的、性價比高的服務器節點來擴展整體能力。這催生了對于高密度、低功耗、易管理服務器的需求。
- 存儲與計算分離趨勢:為了更靈活地配置資源和優化成本,現代大數據架構中,專門用于海量數據存儲的服務器(存儲優化型,通常配備大量硬盤)和專門用于高強度計算的服務器(計算優化型,通常配備強大的CPU和內存)正逐漸走向解耦。
- 硬件加速:為應對機器學習、實時流處理等特定場景,在服務器中集成GPU、FPGA或專用AI芯片進行異構計算加速,已成為提升大數據處理效率的重要手段。
###
服務器,這個看似傳統的IT概念,在大數據時代被賦予了新的生命與內涵。它從孤膽英雄轉變為集群戰士,從通用平臺細分為專業角色。理解服務器,不僅是理解一臺高性能計算機,更是理解大數據龐大身軀下的肌肉與骨骼。它是承載數據洪流的方舟,也是點燃智能計算的引擎,構成了我們探索數據宇宙最堅實的起點。